JAVA8 新特性
![]()
❕❗❗❕ 所有的demo可见 GITHUB
Lambda
什么是Lambda
Lambda 表达式(lambda expression)是一个匿名函数,Lambda表达式基于数学中的λ演算得名,直接对应于其中的lambda抽象(lambda abstraction),是一个匿名函数,即没有函数名的函数。Lambda表达式可以表示闭包。
什么是闭包
闭包就是能够读取其他函数内部变量的函数。例如在javascript中,只有函数内部的子函数才能读取局部变量,所以闭包可以理解成**“定义在一个函数内部的函数“**。
优势
Lambda 表达式主要用来定义行内执行的方法类型接口
Lambda 表达式免去了使用匿名方法的麻烦,并且给予Java简单但是强大的函数化的编程能力。
例子
public class LambdaDemo2 {
public static void main(String[] args) {
int[] nums = {1, 2, 3, 4, 5};
Arrays.stream(nums).forEach(value -> System.out.println(value));
}
}
此处的
value -> System.out.println(value)
就是典型的Lambda表达式
Lambda使用中的问题
从lambda 表达式引用的本地变量必须是最终变量或实际上的最终变量
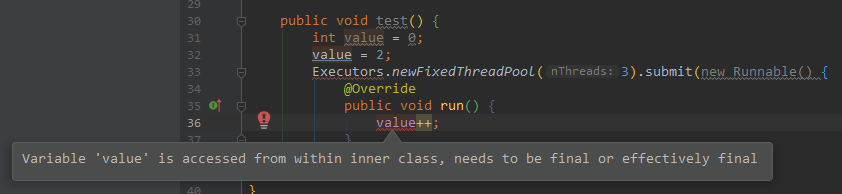
第一个问题,为什么存在这样的限制?
要回答这个问题,我们需要首先明白,匿名内部类外面的value和里面的value是同一个内存地址中的数据么?
很明显不是,因为我们都知道,局部变量存在于栈帧的局部变量表中,一旦方法结束,栈帧被销毁,这个变量(这份数据)就不再存在,但是匿名内部类中的value可能在栈帧销毁后继续存在(比如在这个例子中,匿名内部类被提交到了线程池中)。
所以,只有一个可能,在匿名内部类被创建的时候,被捕获的局部变量发生了复制。如果我们允许在匿名内部类中执行value++操作,带来的后果就是,匿名内部类中的value的拷贝被更新了,但是原先的value不会受到任何影响(因为它可能已经不存在了)——你看上去好像两个value是同一个地址,同一份数据,但是实际上发生了拷贝,和方法调用的值传递如出一辙。这是很可怕的一件事情,它会让你误以为,在匿名内部类中执行value++会改变原先的局部变量value。
第二个问题:那为什么Java 8之后我可以不写final了呢?
如下图
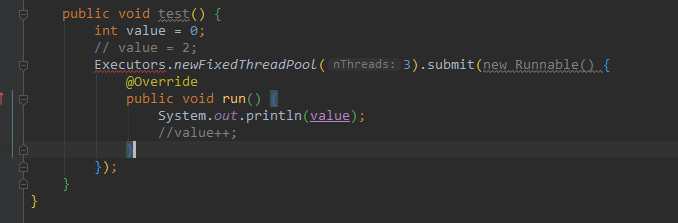
Java 8引入了lambda表达式,我们从此可以非常方便地编写大量的小代码块,但是在捕获外围的局部变量这件事上,lambda表达式和匿名内部类没有任何区别——被捕获的局部变量必须是final的。这就带来了一个问题,继续坚持把局部变量声明成final的话,烦也烦死了。 因此,JLS做出了一个妥协:
假如一个局部变量在整个生命周期中都没有被改变(指向),那么它就是effectively final的——换句话说,不是final,胜似final。这样的局部变量也允许被lambda表达式或者匿名内部类所捕获,不过只能看不能摸——可以读取,但是不能修改。
StreamAPI
Java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。
Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。
+--------------------+ +------+ +------+ +---+ +-------+
| stream of elements +-----> |filter+-> |sorted+-> |map+-> |collect|
+--------------------+ +------+ +------+ +---+ +-------+
以上的流程转换为 Java 代码为:
List<Integer> transactionsIds =
widgets.stream()
.filter(b -> b.getColor() == RED)
.sorted((x,y) -> x.getWeight() - y.getWeight())
.mapToInt(Widget::getWeight)
.sum();
什么是 Stream?
Stream(流)是一个来自数据源的元素队列并支持聚合操作
- 元素是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算。
- 数据源 流的来源。 可以是集合,数组,I/O channel, 产生器generator 等。
- 聚合操作 类似SQL语句一样的操作, 比如filter, map, reduce, find, match, sorted等。
和以前的Collection操作不同, Stream操作还有两个基础的特征:
- Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。
- 内部迭代: 以前对集合遍历都是通过Iterator或者For-Each的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式, 通过访问者模式(Visitor)实现。
如何生成Stream
// stream 生成流
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd", "", "jkl");
List<String> filtered = strings.stream()
.filter(string -> !string.isEmpty())
.collect(Collectors.toList());
System.out.println(strings);
System.out.println(filtered);
System.out.println("===============");
如上述代码,使用一个String的List数组,使用stream方法生成,并使用流式操作返回了一个stream流。输出如下
[abc, , bc, efg, abcd, , jkl]
[abc, bc, efg, abcd, jkl]
===============
常用Stream
forEach
Java8的Stream中使用 ‘forEach’ 来迭代流中的每个数据
// forEach
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd", "", "jkl");
strings.stream()
.forEach(string -> System.out.println(string));
System.out.println("===============");
//输出
abc
bc
efg
abcd
jkl
===============
map
用于映射每个元素到对应的结果(对流中的每个元素做操作后返回流)
// map
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd", "", "jkl");
strings.stream()
.map(string -> string + "Map")
.forEach(string -> System.out.println(string));
System.out.println("===============");
// 输出
abcMap
Map
bcMap
efgMap
abcdMap
Map
jklMap
===============
filter
用于通过设置的条件过滤出元素,filter中的匿名函数为true时,stream中的数据保留,false时,该数据被过滤
// filter
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd", "", "jkl");
strings.stream()
.filter(s -> s.contains("b"))
.forEach(s -> System.out.println(s));
System.out.println("===============");
// 输出
abc
bc
abcd
===============
limit
获取指定数量的流,下述代码获取了原有流中的前两个数据
// limit 于获取指定数量的流
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd", "", "jkl");
strings.stream()
.limit(2)
.forEach(s -> System.out.println(s));
System.out.println("===============");
//输出
abc
===============
并行流parallel
采用并行流收集元素到集合中时。
parallelStream提供了流的并行处理,它是Stream的另一重要特性,其底层使用Fork/Join框架实现。简单理解就是多线程异步任务的一种实现。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.stream()
.forEach(num -> System.out.println(" >>>> " + num));
System.out.println("---------");
numbers.parallelStream()
.forEach(num -> System.out.println(" >>>> " + num));
System.out.println("---------");
numbers.parallelStream()
.forEach(num -> System.out.println(Thread.currentThread().getName() + " >>>> " + num));
System.out.println("=========");
上述代码使用了分别采用了并行流和普通流式操作。从下面的输出可以看出:
普通的流式操作输出的数字是按照顺序输出的。单线程顺序执行。
并行流的输出是无序的,而且可以看出是用不同线程执行了输出。
>>>> 1
>>>> 2
>>>> 3
>>>> 4
>>>> 5
>>>> 6
>>>> 7
>>>> 8
>>>> 9
---------
>>>> 6
>>>> 5
>>>> 3
>>>> 4
>>>> 2
>>>> 7
>>>> 8
>>>> 1
>>>> 9
---------
main >>>> 6
ForkJoinPool.commonPool-worker-1 >>>> 8
ForkJoinPool.commonPool-worker-4 >>>> 2
ForkJoinPool.commonPool-worker-5 >>>> 3
ForkJoinPool.commonPool-worker-2 >>>> 7
ForkJoinPool.commonPool-worker-3 >>>> 5
ForkJoinPool.commonPool-worker-4 >>>> 4
ForkJoinPool.commonPool-worker-1 >>>> 1
main >>>> 9
=========
注意:最好调用collect方法,采用Foreach方法或者map方法可能会出现线程安全问题
collect
Collectors 类实现了很多归约操作,例如将流转换成集合和聚合元素。Collectors 可用于返回列表或字符串:
// Collectors
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd", "", "jkl");
String filtereds = strings.stream()
.filter(string -> !string.isEmpty())
.collect(Collectors.joining("."));
List<String> filteredss = strings
.stream()
.filter(string -> !string.isEmpty())
.collect(Collectors.toList());
System.out.println(filtereds);
System.out.println(filteredss);
System.out.println("===============");
// 输出
abc.bc.efg.abcd.jkl
[abc, bc, efg, abcd, jkl]
===============
数值流
Java*引入了数值流 IntStream, DoubleStream, LongStream,这种流中的元素都是原始数据类型,分别是 int,double,long
IntStream intStream = IntStream.rangeClosed(1, 10);
System.out.println(intStream.sum());
System.out.println("###");
int[] intArr = IntStream.rangeClosed(1, 10).toArray();
Arrays.stream(intArr)
.forEach( value -> System.out.println(value+" "));
System.out.println("###");
OptionalInt intMax = IntStream.rangeClosed(1, 10).max();
System.out.println(intMax.getAsInt());
System.out.println("###");
Optional容器
NullPointerException可以说是每一个 Java 程序员都非常讨厌看到的一个词,针对这个问题, Java 8 引入了一个新的容器类 Optional,可以代表一个值存在或不存在,这样就不用返回容易出问题的 null。之前文章的代码中就经常出现这个类,也是针对这个问题进行的改进。
Optional 类比较常用的几个方法有:
isPresent() :值存在时返回 true,反之 flase
get() :返回当前值,若值不存在会抛出异常
orElse(T) :值存在时返回该值,否则返回 T 的值
Optional 类还有三个特化版本 OptionalInt,OptionalLong,OptionalDouble
流式操作可能出现的问题
foreach中的return函数
foreach()处理集合时不能使用break和continue这两个方法,也就是说不能按照普通的for循环遍历集合时那样根据条件来中止遍历,而如果要实现在普通for循环中的效果时,可以使用return来达到,也就是说如果你在一个方法的lambda表达式中使用return时,这个方法是不会返回的,而只是执行下一次遍历
List<String> list = Arrays.asList("123", "45634", "7892", "abcdef", "a", "b");
list.stream().forEach(e -> {
if (e.length() >= 5) {
return;
}
System.out.println(e);
});
//结果
123
7892
a
b
并行流的陷阱
线程安全
由于并行流使用多线程,则一切线程安全问题都应该是需要考虑的问题,如:资源竞争、死锁、事务、可见性等等。
线程消费
在虚拟机启动时,我们指定了worker线程的数量,整个程序的生命周期都将使用这些工作线程;这必然存在任务生产和消费的问题,如果某个生产者生产了许多重量级的任务(耗时很长),那么其他任务毫无疑问将会没有工作线程可用;更可怕的事情是这些工作线程正在进行IO阻塞。
本应利用并行加速处理的业务,因为工作者不够反而会额外增加处理时间,使得系统性能在某一时刻大打折扣。而且这一类问题往往是很难排查的。我们并不知道一个重量级项目中的哪一个框架、哪一个模块在使用并行流。
串行流
适合存在线程安全问题、阻塞任务、重量级任务,以及需要使用同一事务的逻辑。
并行流
适合没有线程安全问题、较单纯的数据处理任务
CompletableFuture组合式异步编程
Future接口
Future接口在Java 5中被引入,设计初衷是对将来某个时刻会发生的结果进行建模。它建模了一种异步计算,返回一个执行运算结果的引用,当运算结束后,这个引用被返回给调用方。在Future中触发那些潜在耗时的操作把调用线程解放出来,让它能继续执行其他有价值的工作,不需要等待耗时的操作完成。
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 1 创建future
FutureTask<String> stringFuture = new FutureTask<String>(new Callable<String>() {
@Override
public String call() throws Exception {
Thread.sleep(1000);
return "Future--Test";
}
});
// 线程执行
ExecutorService executor = Executors.newCachedThreadPool();
executor.execute(stringFuture);
//2 //向ExecutorService提交一个Callable对象
Future<String> future = executor.submit(new Callable<String>() {
@Override
public String call() throws InterruptedException {
Thread.sleep(1000);
//以异步方式在新线程中执行耗时的操作
return "延时1秒";
}
});
// 注意get会 阻塞
System.out.println(stringFuture.get());
System.out.println(future.get());
executor.shutdown();
}
这种编程方式让你的线程可以在ExecutorService以并发方式调用另一个线程执行耗时操作的同时,去执行一些其他任务。如果已经运行到没有异步操作的结果就无法继续进行时,可以调用它的get方法去获取操作结果。如果操作已经完成,该方法会立刻返回操作结果,否则它会阻塞线程,直到操作完成,返回相应的结果。 为了处理长时间运行的操作永远不返回的可能性,虽然Future提供了一个无需任何参数的get方法,但还是推荐使用重载版本的get方法,它接受一个超时的参数,可以定义线程等待Future结果的时间,而不是永无止境地等待下去
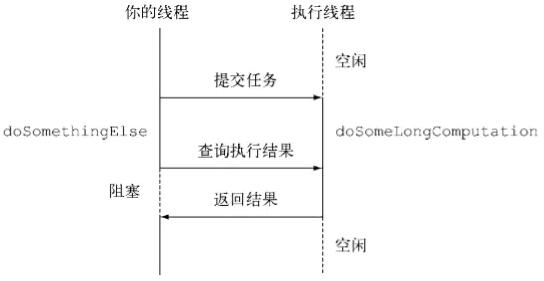
Future接口的局限性
使用Future获得异步执行结果时,要么调用阻塞方法get(),要么轮询看isDone()是否为true,这两种方法都不是很好,因为主线程也会被迫等待。
实现异步API
CompletableFuture的优点是:
- 异步任务结束时,会自动回调某个对象的方法;
- 异步任务出错时,会自动回调某个对象的方法;
- 主线程设置好回调后,不再关心异步任务的执行。
public static void main(String[] args) throws Exception {
Instant start = Instant.now();
// 两个CompletableFuture执行异步查询:
CompletableFuture<String> cfQueryFromSina = CompletableFuture.supplyAsync(() -> {
return queryCode("中国石油", "https://finance.sina.com.cn/code/");
});
CompletableFuture<String> cfQueryFrom163 = CompletableFuture.supplyAsync(() -> {
return queryCode("中国石油", "https://money.163.com/code/");
});
// 用anyOf合并为一个新的CompletableFuture:
CompletableFuture<Object> cfQuery = CompletableFuture.anyOf(cfQueryFromSina, cfQueryFrom163);
/*cfQuery.thenAccept((result) -> {
System.out.println("测试 result" + result);
});*/
// 两个CompletableFuture执行异步查询:
CompletableFuture<Double> cfFetchFromSina = cfQuery.thenApplyAsync((code) -> {
return fetchPrice((String) code, "https://finance.sina.com.cn/price/");
});
CompletableFuture<Double> cfFetchFrom163 = cfQuery.thenApplyAsync((code) -> {
return fetchPrice((String) code, "https://money.163.com/price/");
});
// 用anyOf合并为一个新的CompletableFuture:
CompletableFuture<Object> cfFetch = CompletableFuture.anyOf(cfFetchFromSina, cfFetchFrom163);
// 最终结果:
cfFetch.thenAccept((result) -> {
System.out.println("price: " + result);
Instant end = Instant.now();
System.out.println("获取最终结果花费时间:" + Duration.between(start, end).toMillis() + "ms");
});
// 主线程不要立刻结束,否则CompletableFuture默认使用的线程池会立刻关闭:
Thread.sleep(2000);
}
static String queryCode(String name, String url) {
System.out.println("query code from " + url + "...");
try {
long sleepTime = (long) (Math.random() * 1000);
Thread.sleep(sleepTime);
System.out.println(url + " used time " + sleepTime);
} catch (InterruptedException e) {
}
return "601857";
}
static Double fetchPrice(String code, String url) {
System.out.println("query price from " + url + "...");
try {
long sleepTime = (long) (Math.random() * 1000);
Thread.sleep(sleepTime);
System.out.println(url + " used time " + sleepTime);
} catch (InterruptedException e) {
}
return 5 + Math.random() * 20;
}
结果:
query code from https://finance.sina.com.cn/code/...
query code from https://money.163.com/code/...
https://finance.sina.com.cn/code/ used time 40
query price from https://money.163.com/price/...
query price from https://finance.sina.com.cn/price/...
https://money.163.com/code/ used time 207
https://finance.sina.com.cn/price/ used time 895
price: 12.113254661738953
获取最终结果花费时间:997ms
https://money.163.com/price/ used time 935
参考: